
The topic LLMs hallucinate the most when you ask them to do this is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Large Language Models are great at faking confidence. You can ask ChatGPT, Gemini, or Claude just about everything in the sun, and in most cases, you’ll get a well-structured, confident-sounding answer right away. However, just because your model sounds confident, it doesn’t necessarily mean it’s right.
We’re all too familiar with LLM hallucinations — the model casually invents a quote, cites sources that don’t exist, or gets dates wrong. You might think that AI hallucinations are a thing of the past and that modern models don’t hallucinate as much, but that’s not the full truth. Certain kinds of requests can send your LLM over the edge, and they show up more often in your daily prompts than you might think.
This simple ChatGPT prompting structure works for any goal, big or small.
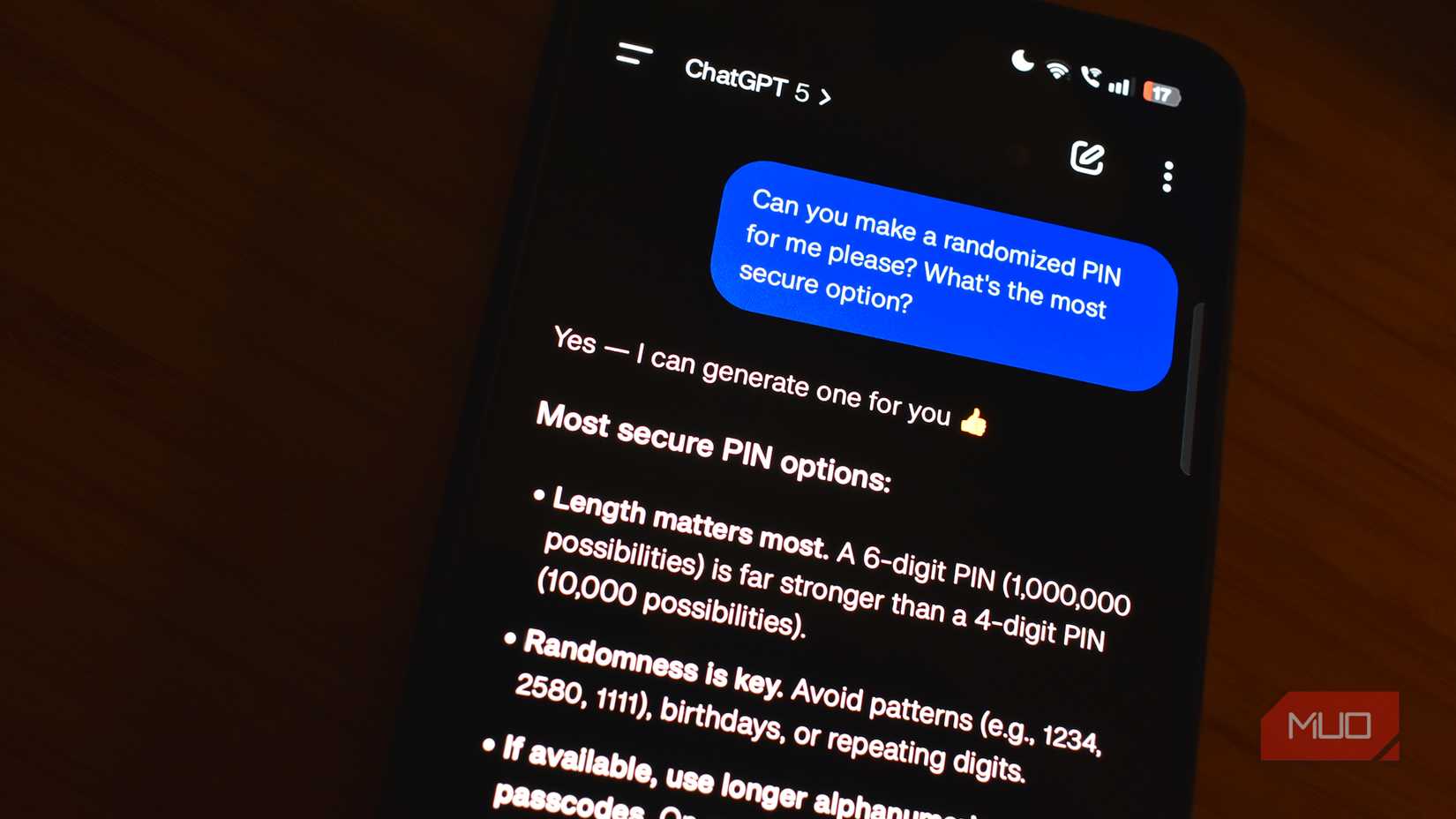
LLMs are built to analyze and generate text, not to calculate. This is a core design choice that applies to almost every LLM out there, and while this works great for prose and everyday communication, it’s not so great with numbers.
Open Resource Application’s April 2026 study benchmarked mathematical calculations against Omni-MATH to find that the average accuracy across models sits at just 0.3861, with GPT-5 mini leading the category. In simple terms, about two out of every three math problems can be partially or entirely hallucinated.
You see, the AI model isn’t solving the equation the way your calculator does. It’s predicting what tokens are statistically likely to show up next. As mentioned before, that works for prose and natural language, but not for mathematics. If you’re asking an LLM to do anything beyond the most basic arithmetic, assume the result needs checking. That AI tool solving complex math problems may not be wrong, but you can’t be sure it’s right.
Data analysis seems the obvious field where an AI model should excel. After all, inspecting, formatting, and transforming data is quite a structured, rule-based task. Turns out, you’ll only get the right answer on this type of task 52.2% of the time, according to the data the GPQA-based scores in the study. This time, though, your best bet is Gemini 3 Pro, which also turned out to be the best model to do daily tasks, scoring the highest in four out of the five tasks they tested. Pairing Gemini with NotebookLM can significantly improve your research reports, too.
In any case, the cause of this is the same as that of AI models being bad at mathematics. LLMs prioritize guessing the next logical token rather than actually processing and calculating the value. That means when a dataset is incomplete or ambiguous, the models fill the gap with what it thinks should go there compared to the accurate, calculated value.
Tutoring is one of the more popular uses of AI currently, but research suggests otherwise. Tests on teaching-style tasks measured against MMLU-Pro show only 0.67 out of 1 on accuracy. Now, a 67% accuracy might sound fine until you realize that it essentially means that every one of three explanations an AI gives you could be wrong. So leaning on it for a rather complicated homework might not be the best option. If you have to, Open Resource Application suggests Gemini 3 Pro.
Health-related questions also fall under the same bracket. LLMs are usually capable of summarizing general information from the web, but a single outdated or unreliable source is all it takes to make their otherwise confident-sounding explanation wrong. A hallucinated dosage, a made-up condition, or a wrong workout cue can be a health risk. For anything that affects your body, fitness, beauty, and overall self-care, let a qualified professional make the right call.
Last but not least, AI models tend to invent information instead of admitting they cannot find it. Specific information queries also averaged 0.67 out of 1 on the MMLU-Pro test. So when you ask about a niche topic with fewer or incomplete sources, the model tends to predict the answer rather than admit they don’t know.
A citation is the worst possible target for the kind of guesswork that AIs do because it has to be exactly right. Whether you’re asking for author names, year, journal, volume, issue, page range, or any specific data point — which usually go in academic or journalist reports — a believable-sounding fake from an AI model is still a fake.
So what does all of this mean? For starters, it doesn’t mean you should hop on the “AI is useless” bandwagon, but you need to stop assuming whatever your AI model told you is right. AI works best when the task at hand is open-ended, creating, or language-focused, where you don’t have a single correct answer. Anything that requires it to be precise and objectively correct, like math, data analysis, teaching, health, and specific fact-checking, has the tendency to make these models hallucinate more.
You can’t start avoiding these AI tools, especially considering they’re some of the best ones around. However, knowing which jobs to hand them and which ones to keep in human hands is what makes the difference. When the stakes are real, and accuracy is required, a real expert is still the right choice.